A key part of the Data Science team mission is to be Squarespace’s source for data-driven strategy. Achieving this mission necessitates incorporating analytics and testing into the decision-making process, often in the form of A/B testing. When used effectively, A/B testing helps organizations make decisions that lead to increases in conversion, engagement, and other metrics, but it is not a silver bullet.
I’ll share two recent Squarespace tests to contextualize the types of tests we run.
Template store categories
We ran a test earlier this year to update our template store categories and recommendations. Updates entailed changes such as renaming “Food & Drink” to “Restaurants” and adding new categories like “Portfolios” and “Blogs.” The updates sought to better match customer intent, thereby creating a better trial experience and ultimately increasing the rate at which users create trials.
Original categories snapshot:
New categories snapshot:

Test results indicated that the treatment group outperformed the control group. As a result of the test results, we rolled out the new categories, which are now live in the template store.
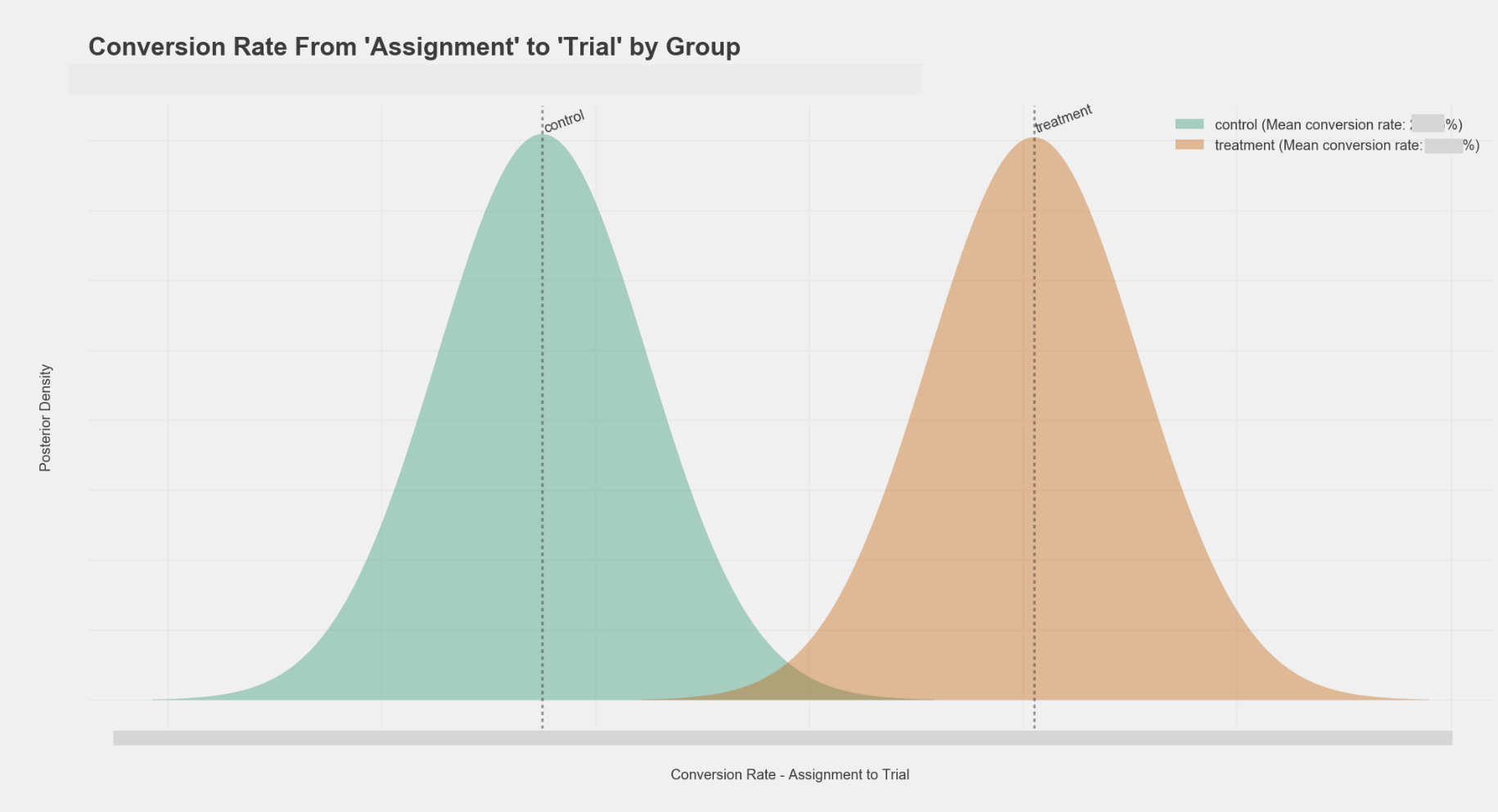
Redacted test results
Trialer prioritization in the email support queue
The second example I’ll share is a test we ran to prioritize trialers in the email support queue. Trialers are people who have activated a free trial subscription, and are evaluating whether to pay for our product. We were looking to test whether receiving faster email support had any impact on trialer conversion to paid customer.
Test results showed there was no meaningful difference in conversion rates as a result of the change. These results could potentially be disappointing. However, we did see a significant increase in customer satisfaction (CSAT) for the prioritized trialer group. Although CSAT was not our success metric, this is useful information in understanding other meaningful impacts of prioritized trialer support.
What did we achieve with the trialer prioritization test?
When an A/B test reveals a high-performing variant, the positive impact of testing is easy to recognize. The Template Store Categories test is an obviously valuable test, since it led to a change in trialer experience with improved trial rates.
But what about the Trialer Prioritization test, which showed no meaningful difference in conversion rates? Our initial hypothesis (that we could impact conversion with prioritized email support) didn’t play out. These scenarios with negative or no effects can feel disappointing — it can feel like a waste of time and resources, and it might also mean the intuition that led us to test the idea to begin with was wrong. People don’t typically like the feeling of wasting time and being wrong, so these testing outcomes are often not celebrated.
However, what might be considered a “failed” A/B test is actually still a win in the context of our original mission: using data to drive strategy. Without testing, we may have decided that the potential conversion impacts of Trialer Prioritization outweighed the tradeoffs and rolled out the program. We would have been making the decision based on incorrect intuition. Instead, testing let us understand that we could improve customer satisfaction, but not conversion.
Squarespace test communications
The way we communicate and track testing at Squarespace embodies this notion that all test results are valuable:
We send out an A/B testing digest as a way to share results from all tests. This ensures there is adequate visibility and that the “success stories” tests aren’t the only results that end up getting shared.
Data Science keeps a log of test outcomes where we track various test attributes and outcomes:
We have internal metrics on what percent of tests show metric improvements, so we know that many tests don’t show clear winners.
We track “test impact” with several available options:
Large – visible in aggregate subs
Zero or marginal – unmeasurably small
Small – unlikely to show up in aggregate subs
Medium – visible when subs are broken into subgroups, but unlikely to be visible in aggregate
TBD
Failed test
Negative impact
Test was run to limit downside risk
The failed test outcome is reserved for true test failures (e.g. assignment bias in test), not disappointing results.
We work with stakeholders to celebrate learning and encourage testing hypotheses. Data Science provides just as thorough analysis on test results with no or negative impacts as we do for tests with positive impacts. Tests with negative impacts can be valuable opportunities for learning, and analytics works to unveil these insights.
Celebrate learning
Smart organizations have the ability to recognize that they are making the right decision, even when it means pulling the plug on a project. If an organization is going to embrace testing to make data-driven decisions, we should shift the narrative to celebrate learning rather than “wins.”
If we don’t celebrate learning, we aren’t truly embracing data-driven strategy. A “negative” test result can give us just as much insight as a “positive” result. At Squarespace, we are passionate about using analytics to develop our strategy, and that means every right decision is a win, not just the ones with flashy outcomes.
